021. 合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:

输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]
示例 2:
输入:l1 = [], l2 = []
输出:[]
示例 3:
输入:l1 = [], l2 = [0]
输出:[0]
提示:
- 两个链表的节点数目范围是
[0, 50] -100 <= Node.val <= 100l1和l2均按 非递减顺序 排列
题意分析
- 二路归并算法
AC Code
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
auto dummy=new ListNode(-1), tail=dummy;
while(l1 && l2)
{
if (l1->val <= l2->val)
{
tail=tail->next=l1;
l1=l1->next;
}
else
{
tail=tail->next=l2;
l2=l2->next;
}
}
if (l1) tail->next=l1;
if (l2) tail->next=l2;
return dummy->next;
}
};
022. 括号生成
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
有效括号组合需满足:左括号必须以正确的顺序闭合。
示例 1:
输入:n = 3
输出:["((()))","(()())","(())()","()(())","()()()"]
示例 2:
输入:n = 1
输出:["()"]
提示:
1 <= n <= 8
题意分析
- 任意前缀序列中左括号数量 \ge 右括号数量
- 左右括号数量相等
-
$l_{cnt}<n$
- $l_{cnt} \ge r_{cnt} \ \&\& \ r_{cnt}<n$
AC Code
class Solution {
public:
vector<string> ans;
vector<string> generateParenthesis(int n) {
dfs(n,0,0,"");
return ans;
}
void dfs(int n, int lc, int rc, string seq)
{
if (lc==n && rc==n) ans.push_back(seq);
else
{
if (lc<n) dfs(n,lc+1,rc,seq+'(');
if (rc<lc && rc<n) dfs(n,lc,rc+1,seq+')');
}
}
};
023. 合并K个排序链表
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]]
输出:[1,1,2,3,4,4,5,6]
解释:链表数组如下:
[
1->4->5,
1->3->4,
2->6
]
将它们合并到一个有序链表中得到。
1->1->2->3->4->4->5->6
示例 2:
输入:lists = []
输出:[]
示例 3:
输入:lists = [[]]
输出:[]
提示:
k == lists.length0 <= k <= 10^40 <= lists[i].length <= 500-10^4 <= lists[i][j] <= 10^4lists[i]按 升序 排列lists[i].length的总和不超过10^4
题意分析
- 用堆来找最小元素
AC Code
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
struct Cmp
{
bool operator() (ListNode* a, ListNode* b)
{
return a->val>b->val;
}
};
ListNode* mergeKLists(vector<ListNode*>& lists) {
priority_queue<ListNode*,vector<ListNode*>,Cmp> heap;
auto dummy = new ListNode(-1),tail=dummy;
for (auto l:lists) if (l) heap.push(l);
while(heap.size())
{
auto t=heap.top();
heap.pop();
tail=tail->next=t;
if (t->next) heap.push(t->next);
}
return dummy->next;
}
};
024. 两两交换链表中的节点
给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。
你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
示例 1:

输入:head = [1,2,3,4]
输出:[2,1,4,3]
示例 2:
输入:head = []
输出:[]
示例 3:
输入:head = [1]
输出:[1]
提示:
- 链表中节点的数目在范围
[0, 100]内 0 <= Node.val <= 100
AC Code
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* swapPairs(ListNode* head) {
auto dummy = new ListNode(-1);
dummy->next=head;
for (auto p=dummy; p->next && p->next->next;)
{
auto a=p->next,b=a->next;
p->next=b;
a->next=b->next;
b->next=a;
p=a;
}
return dummy->next;
}
};
025. K 个一组翻转链表
给你一个链表,每 k 个节点一组进行翻转,请你返回翻转后的链表。
k 是一个正整数,它的值小于或等于链表的长度。
如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
进阶:
- 你可以设计一个只使用常数额外空间的算法来解决此问题吗?
- 你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
示例 1:

输入:head = [1,2,3,4,5], k = 2
输出:[2,1,4,3,5]
示例 2:
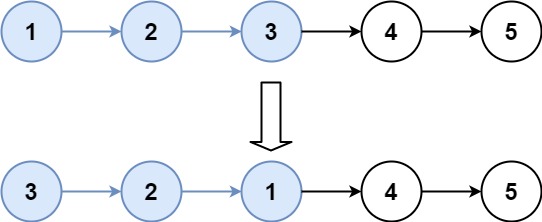
输入:head = [1,2,3,4,5], k = 3
输出:[3,2,1,4,5]
示例 3:
输入:head = [1,2,3,4,5], k = 1
输出:[1,2,3,4,5]
示例 4:
输入:head = [1], k = 1
输出:[1]
提示:
- 列表中节点的数量在范围
sz内 1 <= sz <= 50000 <= Node.val <= 10001 <= k <= sz
AC Code
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseKGroup(ListNode* head, int k) {
auto dummy = new ListNode(-1);
dummy->next=head;
for (auto p=dummy;;)
{
auto q=p;
for (int i=0; i<k && q; i++) q=q->next;
if (!q) break;
auto a=p->next, b=a->next;
for (int i=0; i<k-1; i++)
{
auto c=b->next;
b->next=a;
a=b,b=c;
}
auto c=p->next;
p->next=a;
c->next=b;
p=c;
}
return dummy->next;
}
};
026. 删除排序数组中的重复项
给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝
int len = removeDuplicates(nums);
// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
for (int i = 0; i < len; i++) {
print(nums[i]);
}
示例 1:
输入:nums = [1,1,2]
输出:2, nums = [1,2]
解释:函数应该返回新的长度 2 ,并且原数组 nums 的前两个元素被修改为 1, 2 。不需要考虑数组中超出新长度后面的元素。
示例 2:
输入:nums = [0,0,1,1,1,2,2,3,3,4]
输出:5, nums = [0,1,2,3,4]
解释:函数应该返回新的长度 5 , 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4 。不需要考虑数组中超出新长度后面的元素。
提示:
0 <= nums.length <= 3 * 104-104 <= nums[i] <= 104nums已按升序排列
AC Code
class Solution {
public:
int removeDuplicates(vector<int>& nums) {
int k=0;
for (int i=0; i<nums.size(); i++)
if (!i || nums[i]!=nums[i-1])
nums[k++]=nums[i];
return k;
}
};
027. 移除元素
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参作任何拷贝
int len = removeElement(nums, val);
// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
for (int i = 0; i < len; i++) {
print(nums[i]);
}
示例 1:
输入:nums = [3,2,2,3], val = 3
输出:2, nums = [2,2]
解释:函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。你不需要考虑数组中超出新长度后面的元素。例如,函数返回的新长度为 2 ,而 nums = [2,2,3,3] 或 nums = [2,2,0,0],也会被视作正确答案。
示例 2:
输入:nums = [0,1,2,2,3,0,4,2], val = 2
输出:5, nums = [0,1,4,0,3]
解释:函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。注意这五个元素可为任意顺序。你不需要考虑数组中超出新长度后面的元素。
提示:
0 <= nums.length <= 1000 <= nums[i] <= 500 <= val <= 100
AC Code
class Solution {
public:
int removeElement(vector<int>& nums, int val) {
int k=0;
for (int i=0; i<nums.size(); i++)
{
if (nums[i]!=val)
nums[k++]=nums[i];
}
return k;
}
};
028. 实现 strStr()
实现 strStr() 函数。
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串出现的第一个位置(下标从 0 开始)。如果不存在,则返回 -1 。
说明:
当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。
对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与 C 语言的 strstr() 以及 Java 的 indexOf() 定义相符。
示例 1:
输入:haystack = "hello", needle = "ll"
输出:2
示例 2:
输入:haystack = "aaaaa", needle = "bba"
输出:-1
示例 3:
输入:haystack = "", needle = ""
输出:0
提示:
0 <= haystack.length, needle.length <= 5 * 104haystack和needle仅由小写英文字符组成
AC Code
class Solution {
public:
int strStr(string haystack, string needle) {
if(needle.empty()) return 0;
int n=haystack.size(), m=needle.size();
haystack=' '+haystack;
needle=' '+needle;
vector<int> next(m+1); //KMP算法
for (int i=2, j=0; i<m; i++)
{
while(j && needle[i]!=needle[j+1]) j=next[j];
if (needle[i]==needle[j+1]) j++;
next[i]=j;
}
for (int i=1,j=0; i<=n; i++)
{
while(j && haystack[i]!=needle[j+1]) j=next[j];
if (haystack[i]==needle[j+1]) j++;
if (j==m) return i-m;
}
return -1;
}
};
029. 两数相除
给定两个整数,被除数 dividend 和除数 divisor。将两数相除,要求不使用乘法、除法和 mod 运算符。
返回被除数 dividend 除以除数 divisor 得到的商。
整数除法的结果应当截去(truncate)其小数部分,例如:truncate(8.345) = 8 以及 truncate(-2.7335) = -2
示例 1:
输入: dividend = 10, divisor = 3
输出: 3
解释: 10/3 = truncate(3.33333..) = truncate(3) = 3
示例 2:
输入: dividend = 7, divisor = -3
输出: -2
解释: 7/-3 = truncate(-2.33333..) = -2
提示:
- 被除数和除数均为 32 位有符号整数。
- 除数不为 0。
- 假设我们的环境只能存储 32 位有符号整数,其数值范围是 [−2^{31}, 2^{31} − 1]。本题中,如果除法结果溢出,则返回 2^{31} − 1。
AC Code
class Solution {
public:
int divide(int x, int y) {
typedef long long ll;
vector<ll> exp;
bool flag=0;
if (x<0 && y>0 || x>0 && y<0) flag=1;
if (x == -2147483648 && y == -1) return 2147483647;
if (x == -2147483648 && y == 1) return -2147483648;
ll a=abs(x), b=abs(y);
for (ll i=b; i<=a; i+=i) exp.push_back(i);
ll res=0;
for (int i=exp.size()-1; i>=0; i--)
{
if (a>=exp[i])
{
a-=exp[i];
res+=1<<i;
}
}
if (flag) res=-res;
if (res > INT_MAX || res < INT_MIN) res = INT_MAX;
return res;
}
};
030. 串联所有单词的子串
给定一个字符串 s 和一些 长度相同 的单词 words 。找出 s 中恰好可以由 words 中所有单词串联形成的子串的起始位置。
注意子串要与 words 中的单词完全匹配,中间不能有其他字符 ,但不需要考虑 words 中单词串联的顺序。
示例 1:
输入:s = "barfoothefoobarman", words = ["foo","bar"]
输出:[0,9]
解释:
从索引 0 和 9 开始的子串分别是 "barfoo" 和 "foobar" 。
输出的顺序不重要, [9,0] 也是有效答案。
示例 2:
输入:s = "wordgoodgoodgoodbestword", words = ["word","good","best","word"]
输出:[]
示例 3:
输入:s = "barfoofoobarthefoobarman", words = ["bar","foo","the"]
输出:[6,9,12]
提示:
1 <= s.length <= 104s由小写英文字母组成1 <= words.length <= 50001 <= words[i].length <= 30words[i]由小写英文字母组成
题意分析
- 所有的单词的长度一样,滑动窗口
- 哈希表维护:加一个单词,删一个单词,保证每个单词的唯一性
AC Code
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
vector <int> res;
if (words.empty()) return res;
int n=s.size(), m=words.size(), w=words[0].size();
unordered_map<string,int> tot;
for (auto& word:words) tot[word]++;
for (int i=0; i<w; i++)
{
unordered_map<string, int> wd; //滑动窗口
int cnt=0;
for (int j=i; j+w<=n; j+=w)
{
if (j>=i+m*w)
{
auto word =s.substr(j-m*w,w);
wd[word]--;
if(wd[word]<tot[word]) cnt--; //删除最前面的单词
}
auto word = s.substr(j,w); //加入新单词
wd[word]++;
if (wd[word]<=tot[word]) cnt++;
if (cnt==m) res.push_back(j-(m-1)*w);
}
}
return res;
}
};


0 条评论