工程文件
任务一: 导入包和创建数据集
from math import log
import treePlotter,csv
import numpy as np
def createDataSet1():
data=[
[0, 0, 0, 0, 'yes'],
[0, 1, 0, 1, 'yes'],
[0, 2, 1, 0, 'no'],
[0, 2, 1, 1, 'no'],
[0, 1, 1, 0, 'no'],
[1, 2, 1, 0, 'yes'],
[1, 0, 0, 1, 'yes'],
[1, 1, 1, 1, 'yes'],
[1, 2, 0, 0, 'yes'],
[2, 1, 1, 0, 'yes'],
[2, 0, 0, 0, 'yes'],
[2, 1, 0, 0, 'yes'],
[2, 0, 0, 1, 'no'],
[2, 1, 1, 1, 'no']
]
features=['weather','temperature','humidity','wspeed']
return data,features
data1,features1 = createDataSet1()
features1
任务二:ID3树
2.1 完成香农熵计算函数
ID3 以信息熵的增益来作为分类的依据。假设样本集 D 中第 k 类样本占比 pk ,可计算其对应信息熵为:

def calcShannonEnt(dataSet):
"""
函数:计算数据集香农熵
参数:dataSet:数据集
labels:数据标签
返回:shannonEnt 数据集对应的香农熵
"""
numEntries = len(dataSet) #样本数
labelCounts = {} #统计不同label出现次数的字典(key为label,value为出现次数)
shannonEnt = 0.0
#计算labelCounts
for featVec in dataSet:
# 获取当前这条数据的label值
currentLabel = featVec[-1]
# 是新label,则在标签字典中新建对应的key,value的对应出现的次数,初始化为0
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
# 已有则当前label出现次数+1
labelCounts[currentLabel] += 1
### START CODE HERE ###
for keys in labelCounts:
shannonEnt -= (labelCounts[keys]/numEntries)*log(labelCounts[keys]/numEntries,2)
### END CODE HERE ###
return shannonEnt
print(calcShannonEnt(data1))
data1[0][-1] = 'maybe' #尝试增加一个分类选项,观察熵变化
print(calcShannonEnt(data1))
#out:0.9402859586706309 ; 1.2638091738835462
data1[0][-1] = 'yes' #还原
输出
0.9402859586706309
1.2638091738835462
2.2完成基本功能函数
- splitDataSet:用于在决策树每个分支,将特征取某个值的所有数据划分为一个数据集
def splitDataSet(dataSet, axis, value):
"""
函数:将axis列属性值为value的组合为一个数据集,并删除第axis列特征信息
参数:axis:特征列索引
value:待分离的特征取值
返回:retDataSet:被分割出来的数据集
"""
retDataSet = []
for data in dataSet:
# 如果数据集的第axis列值等于value,保留条数据,并删除第axis列特征信息
if data[axis] == value:
# 获取被降维特征前面的所有特征
reducedFeatVec = data[:axis]
# 接上被降维特征后面的所有特征
reducedFeatVec.extend(data[axis + 1:])
# 新的降维数据加入新的返回数据集中
retDataSet.append(reducedFeatVec)
return retDataSet
splitDataSet(data1,0,1)
#out:[[2, 1, 0, 'yes'], [0, 0, 1, 'yes'], [1, 1, 1, 'yes'], [2, 0, 0, 'yes']]
输出
[[2, 1, 0, 'yes'], [0, 0, 1, 'yes'], [1, 1, 1, 'yes'], [2, 0, 0, 'yes']]
2.3用信息增益选择待分类的特征
那么假设用离散属性a有V个可能值,划分能产生V个分支,每个分支包含的数据记为 Dv 。 由此我们可以得出用属性a对样本集D划分的信息增益计算公式:

def chooseBestFeature_ID3(dataSet):
"""
函数:利用香农熵,计算所有可能划分的信息增益,输出当前数据集最好的分类特征
参数:dataSet
返回:bestFeature:最优特征的index(下标)
"""
numFeatures = len(dataSet[0]) - 1 #特征数
baseEntropy = calcShannonEnt(dataSet) #Ent(D)
bestInfoGain = 0.0 #信息增益
bestFeature = -1 #最好信息增益特征
#遍历每个特征
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList) #第i个特征的可能取值
newEntropy = 0.0
### STARD CODE HERE ###
#计算以第i个特征划分产生的infoGain
for value in uniqueVals:
subDataSet = splitDataSet(dataSet,i,value)
prob = float(len(subDataSet)/float(len(dataSet)))
newEntropy += prob*calcShannonEnt(subDataSet)
infoGain = bestInfoGain - newEntropy
#如果大于当前bestInfoGain,则保留当前划分为最优划分
if infoGain > bestFeature:
bestInfoGain = infoGain
bestFeature = i
### END CODE HERE ###
return bestFeature
chooseBestFeature_ID3(data1)
#out:0
输出
0
2.4生成ID3决策树
接下来我们可以用 递归 的方法生成决策树,其基本流程如下:
- 划分条件:自根结点开始,通过选择出最佳属性进行划分树结构,并递归划分;
-
停止条件:当前结点都是同一种类型;当前结点后为空,或者所有样本在所有属性上取值相同,无法划分;
这是通用的创建决策树的函数,根据参数chooseBestFeature的不同,得到不同算法的决策树,当前任务中参数为刚刚编写的 chooseBestFeature_ID3。
备注:
此处代码实现的ID3树,每个结点不能选取祖先结点用过的分类特征。 而实际上结点的不同子树,是有可能选取同样的分类特征的。 原因在于代码实现的 del (features[bestFeat]) 会导致一个特征被选用后,之后就再不能被选用。可以通过在递归时传入features的一份复制来避免这个问题。
def createTree(dataSet, features, chooseBestFeature):
"""
函数:递归地根据数据集和数据特征名创建决策树
参数:chooseBestFeature:函数作为参数,通过chooseBestFeature(dataSet)调用,
根据参数的不同,获取由ID3或C4.5算法选择的最优特征的index
返回:myTree:由集合表示的决策树
"""
classList = [data[-1] for data in dataSet] #当前数据集的所有标签
bestFeat = chooseBestFeature(dataSet) #当前数据集最优特征
bestFeatName = features[bestFeat] #最优特征的标签名
myTree = {bestFeatName: {}} #构造当前结点——最优特征:子结点集合
bestFeatValues = set([data[bestFeat] for data in dataSet]) #最优特征可能的取值,set去重
del (features[bestFeat]) #删除已用过的分类标签
### STARD CODE HERE ###
# 如果当前dataSet所有的标签相同,此结点分类完毕,结束决策,返回分类标签
if classList.count(classList[0])==len(classList):
return classList[0]
if len(dataSet[0])==0:
return classList[0]
if len(features)==1:
return classList[0]
# 否则,为每个最优特征取值,递归地创建子树
for value in bestFeatValues:
subFeatures = features.copy()
myTree[bestFeatName][value] = createTree(splitDataSet(dataSet,bestFeat,value),subFeatures,chooseBestFeature)
### END CODE HERE ###
return myTree
data1, labels1 = createDataSet1()
ID3Tree = createTree(data1, labels1,chooseBestFeature_ID3)
treePlotter.createPlot(ID3Tree)
输出

任务三:C4.5树
ID3用信息增益选择属性的方式会让他对取值数目较多的属性产生偏好,接下来我们通过一个直观的例子来说明。
假设数据集变成如下所示,某个属性(如风速)变为每个样本一个值的情况,构建一个ID3树。
def createDataSet2():
data=[
[0, 0, 1, 0, 'yes'],
[1, 1, 0, 1, 'yes'],
[0, 0, 0, 2, 'no'],
[0, 1, 1, 3, 'no'],
[1, 1, 1, 4, 'yes']
]
features2=['weather','temperature','humidity','wspeed']
return data,features2
data2, features2 = createDataSet2()
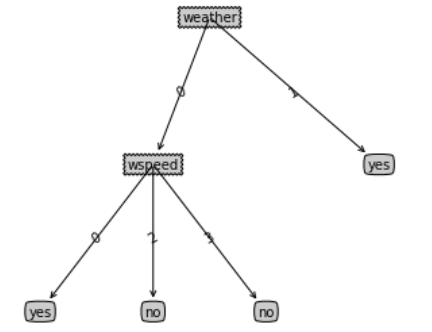
ID3Tree = createTree(data2, features2, chooseBestFeature_ID3)
treePlotter.createPlot(ID3Tree)
输出

ID3树利用了该属性为每一个样本创建了分支,这样得到的决策树显然泛化性会很差。 为了进行改进,我们可以设想为信息增益增加一个类似于正则项的惩罚参数,在特征取值多时,降低信息增益。
信息增益比 = 惩罚参数 * 信息增益
C4.5算法为属性定义一个Intrinsic Value(IV)来构建这个惩罚参数:
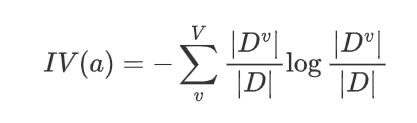
其数学意义为:以特征a作为随机变量的熵的倒数。
假设某个属性将样本等分为x份,可得其


观察函数图像会发现,样本划分越多,x越大,其值越大,于是可将信息增益改进为信息增益比

任务3.1 用信息增益比选择分类特征
def chooseBestFeature_C45(dataSet):
"""
函数:计算所有可能划分的信息增益比,输出当前数据集最好的分类特征
参数:dataSet
返回:bestFeature:最优特征的index(下标)
"""
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
IV = 0.0
### STARD CODE HERE ###
# 计算以第i个特征划分的infoGain,以及其IV
for value in uniqueVals:
subDataSet = splitDataSet(dataSet,i,value)
prob = float(len(subDataSet)/float(len(dataSet)))
newEntropy += prob*calcShannonEnt(subDataSet)
IV -= prob*log(prob,2)
if not IV:
IV = -0.99 * log(0.99,2) - 0.01 * log(0.01,2)
# 计算GainRatio衰减
infoGain = float(baseEntropy-newEntropy)/IV
# 如果大于当前最优,则保留当前划分为最优划分
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestFeature = i
### END CODE HERE ###
return bestFeature
任务3.2 生成C4.5树
data2, labels2 = createDataSet2()
C45Tree = createTree(data2, labels2, chooseBestFeature_C45)
treePlotter.createPlot(C45Tree)
任务四:CART
前面的实验我们发现ID3和C4.5算法在用于分类问题是有效的,那么决策树可以适用于回归问题吗?
CART(Classification and regression tree)如其名,便是可以既可以用于解决分类问题,又可以用于解决回归问题的决策树算法。
在解决分类问题时:
ID3/C4.5基于信息论熵模型选择一个离散的特征进行分类,根据特征取值数目一次性划分若干子结点,然后子结点的数据集将不再包含这个特征,这个特征不再参与接下来的分类,这意味着这种决策树模型是不能直接处理连续取值的特征的,除非划分区间将其离散化。
CART则根据基尼系数(Gini Index) 为连续或离散的特征选择一个划分点,产生左右两个分支,生成二叉树。在产生分支后,仍可以再利用这个特征,参与接下来的分类,产生下一个分支。用叶子结点样本最多的标签作为预测输出。
在解决回归问题时:
CART根据平方损失选择最优划分特征和划分点,并用叶子结点样本标签均值作为预测输出。
接下来我们来具体实现CART回归树,并尝试用于解决一个分类问题。
任务4.1 iris数据集读取和预处理任务
Iris数据集即鸢尾属植物数据集,该数据集测量了所有150个样本的4个特征,分别是:
sepal length(花萼长度)
sepal width(花萼宽度)
petal length(花瓣长度)
petal width(花瓣宽度)
标签为其种属:Iris Setosa,Iris Versicolour,Iris Virginica。该数据集被广泛用于分类算法示例,我们可以看到其4个特征取值均是连续的。数据集存储在 iris.csv 文件中,我们从中手动划分一部分作为训练集。
def createDataSetIris():
'''
函数:获取鸢尾花数据集,以及预处理
返回:
Data:构建决策树的数据集(因打乱有一定随机性)
Data_test:手动划分的测试集
featrues:特征名列表
labels:标签名列表
'''
labels = ["setosa","versicolor","virginica"]
with open('/content/drive/MyDrive/ML_HW/HW6_decision_tree/iris.csv','r') as f:
rawData = np.array(list(csv.reader(f)))
features = np.array(rawData[0,1:-1])
dataSet = np.array(rawData[1:,1:]) #去除序号和特征列
np.random.shuffle(dataSet) #打乱(之前如果不加array()得到的会是引用,rawData会被一并打乱)
return rawData[1:,1:], dataSet, features, labels
rawData, data, features, labels = createDataSetIris()
print(rawData[0]) #['5.1' '3.5' '1.4' '0.2' 'setosa']
print(data[0])
print(features) #['Sepal.Length' 'Sepal.Width' 'Petal.Length' 'Petal.Width']
print(labels) #['setosa', 'versicolor', 'virginica']
['5.1' '3.5' '1.4' '0.2' 'setosa']
['6.2' '2.9' '4.3' '1.3' 'versicolor']
['Sepal.Length' 'Sepal.Width' 'Petal.Length' 'Petal.Width']
['setosa', 'versicolor', 'virginica']
4.2 完成基尼指数计算函数
数据集D的基尼值(Gini Index)计算公式如下:
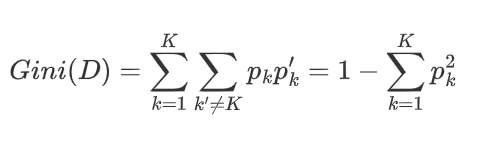
其数学意义为,从数据集中任选两个样本,类别不一致的概率。其值越小,数据集纯度越高。
数据集D某个划分a的基尼系数计算如下:

def calcGiniIndex(dataSet):
'''
函数:计算数据集基尼值
参数:dataSet:数据集
返回: Gini值
'''
counts = [] #每个标签在数据集中出现的次数
count = len(dataSet) #数据集长度
for label in labels:
counts.append([d[-1] == label for d in dataSet].count(True))
### STARD CODE HERE ###
gini = 0.0
temp = 0.0
for i in counts:
temp += (i/count)**2
gini = 1.0-temp
### END CODE HERE ###
return gini
calcGiniIndex(rawData)
#out:0.6666666666666667
输出
0.6666666666666667
4.3 完成基本功能函数
- binarySplitDataSet: 和ID3,C4.5不同,CART每个划分均为二分,且不删除特征信息。这里由于已知数据集特征取值全是连续取值型的, 对算法的部分功能进行了并不严谨的简化。实际应用中的CART还应该判断特征取值是否离散,若离散,并把feature等于和不等于value的数据划分为两个数据集。
- classificationLeaf:用于分类命题,此处实现的是多数表决器,叶结点输出数据集最多的标签作为分类。如果是用于回归问题,叶结点应该输出的是数据集列的均值作为回归预测。
def binarySplitDataSet(dataSet, feature, value):
'''
函数:将数据集按特征列的某一取值换分为左右两个子数据集
参数:dataSet:数据集
feature:数据集中某一特征列
value:该特征列中的某个取值
返回:左右子数据集
'''
matLeft = [d for d in dataSet if d[feature] <= value]
matRight = [d for d in dataSet if d[feature] > value]
return matLeft,matRight
binarySplitDataSet(rawData,0,"4.3")[0]
#out[array(['4.3', '3', '1.1', '0.1', 'setosa'], dtype='<U12')]
输出
[array(['4.3', '3', '1.1', '0.1', 'setosa'], dtype='<U12')]
def classifyLeaf(dataSet, labels):
'''
函数:求数据集最多的标签,用于结点分类
参数:dataSet:数据集
labels:标签名列表
返回:该标签的index
'''
counts = []
for label in labels:
counts.append([d[-1] == label for d in dataSet].count(True))
return np.argmax(counts) #argmax:使counts取最大值的下标
classifyLeaf(rawData[40:120],labels)
#out:1
输出
1
4.4 用基尼系数选择特征及划分点
CART在这一步选择的不仅是特征,而是特征以及该特征的一个分界点。CART要遍历所有特征的所有样本取值作为分界点的Gini系数,从中找出最优特征和最优划分。
在这里我们进一步地为决策树设定停止条件——阈值。当结点样本树足够小或者Gini增益足够小的时候停止划分,将结点中最多的样本作为结点的决策分类。
def chooseBestSplit(dataSet, labels, leafType=classifyLeaf, errType=calcGiniIndex, threshold=(0.01,4)):
'''
函数:利用基尼系数选择最佳划分特征及相应的划分点
参数:dataSet:数据集
leafType:叶结点输出函数(当前实验为分类)
errType:损失函数,选择划分的依据(分类问题用的就是GiniIndex)
threshold: Gini阈值,样本阈值(结点Gini或样本数低于阈值时停止)
返回:bestFeatureIndex:划分特征
bestFeatureValue:最优特征划分点
'''
thresholdErr = threshold[0] #Gini阈值
thresholdSamples = threshold[1] #样本阈值
err = errType(dataSet)
bestErr = np.inf
bestFeatureIndex = 0 #最优特征的index
bestFeatureValue = 0 #最优特征划分点
### STARD CODE HERE ###
#当数据中输出值都相等时,返回叶结点(即feature=None,value=结点分类)
if err==0:
return None,dataSet[0][-1]
#尝试所有特征的所有取值,二分数据集,计算err(本实验为Gini),保留bestErr
for i in range(len(dataSet[0]) - 1):
uniqueVals = set([example[i] for example in dataSet])
for value in uniqueVals:
leftSet,rightSet = binarySplitDataSet(dataSet, i, value)
if len(leftSet) < thresholdSamples or len(rightSet) < thresholdSamples:
continue
gini = (len(leftSet) * calcGiniIndex(leftSet) + len(rightSet) * calcGiniIndex(rightSet)) / (len(leftSet) + len(rightSet))
if gini < bestErr:
bestErr = gini
bestFeatureIndex = i
bestFeatureValue = value
#检验Gini阈值,若是则不再划分,返回叶结点
if (err - bestErr)<thresholdErr:
return None,labels[leafType(dataSet, labels)]
#检验左右数据集的样本数是否小于阈值,若是则不再划分,返回叶结点
### END CODE HERE ###
return bestFeatureIndex,bestFeatureValue
chooseBestSplit(rawData, labels)
#out:(2, '1.9')
输出
(2,'1.9')
4.5 生成CART
根据参数leafType,errType的不同,生成CART分类树或是CART回归树。
def createTree_CART(dataSet, labels, leafType=classifyLeaf, errType=calcGiniIndex, threshold=(0.01,4)):
'''
函数:建立CART树
参数:同上
返回:CART树
'''
feature,value = chooseBestSplit(dataSet, labels, leafType, errType, threshold)
### STARD CODE HERE ###
#是叶结点则返回决策分类(chooseBestSplit返回None时表明这里是叶结点)
if feature is None:
return value
#否则创建分支,递归生成子树
leftSet,rightSet = binarySplitDataSet(dataSet, feature, value)
myTree = {}
myTree[features[feature]] = {}
myTree[features[feature]]['<=' + str(value) + ' contains' + str(len(leftSet))] = createTree_CART(leftSet, np.array(leftSet)[:,-1], leafType, errType,threshold)
myTree[features[feature]]['>' + str(value) + ' contains' + str(len(rightSet))] = createTree_CART(rightSet, np.array(rightSet)[:,-1], leafType, errType,threshold)
### END CODE HERE ###
return myTree
CARTTree = createTree_CART(data, labels, classifyLeaf, calcGiniIndex, (0.01,4))
treePlotter.createPlot(CARTTree)
输出


0 条评论