0. 论文链接
1. Abstract
- 建立了一个系统来创建语义三维地图
- 使用 ORB SLAM, PSPNet模型
- 基于语义地图构建了一种拓扑地图
2. Introduction
- 通过语义信息的地图帮助机器人理解其所处的环境
- 涉及三维映射与语义分割
2.1 SLAM
同步定位与建图,即:将一个机器人放入未知环境中的未知位置,是否有办法让机器人一边移动一边逐步描绘出此环境完全的地图。
2.2 ORB SLAM
- 基于ORB特征的三维定位与地图构建事件
- ORB:采用FAST算法来检测特征点
- FAST算法核心思想:拿一个点与周围的点进行比较,若与其中大部分点都不一样就可以认为其是一个特征点
基于视觉的语义SLAM主要通过相机实现,不适应外部环境
基于激光雷达适合外部环境,但是成本高且获取的信息量较少
故选择相机实现语义SLAM
使用基于单视觉的SLAM系统ORB SLAM,拥有良好的运动状态鲁棒性和实时性,同时有良好的闭环性。
2.3 PSPNet
金字塔场景解析网络
核心模块是金字塔池化模块( pyramid pooling module),它能够聚合不同区域的上下文信息,从而提高获取全局信息的能力。实验表明这样的先验表示(即指代PSP这个结构)是有效的,在多个数据集上展现了优良的效果

该模块融合了4种不同金字塔尺度的特征,第一行红色是最粗糙的特征–全局池化生成单个bin输出,后面三行是不同尺度的池化特征。为了保证全局特征的权重,如果金字塔共有N个级别,则在每个级别后使用1×1的卷积将对于级别通道降为原本的1/N。再通过双线性插值获得未池化前的大小,最终concat到一起
在PSP模块的基础上,PSPNet的整体架构如下:
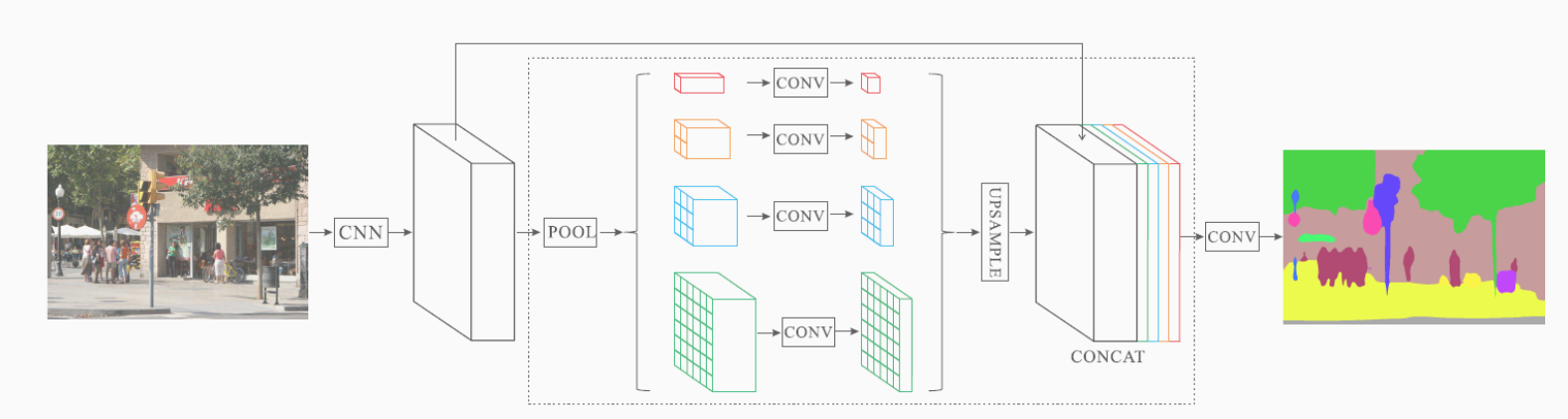
2.4 KITTI 数据集
KITTI数据集由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集。该数据集用于评测立体图像(stereo),光流(optical flow),视觉测距(visual odometry),3D物体检测(object detection)和3D跟踪(tracking)等计算机视觉技术在车载环境下的性能

2.5 主要贡献
- 融合了视觉SLAM地图和语义分割信息来构建大规模下的语义3D地图
- 开发 KITTI数据集
- 现实世界的地标与点云地图进行关联,建立了基于予以地图的拓扑地图
3. Related Work
- 语义SLAM的目标是通过结合集合信息和语义信息来构造具有语义意义的映射
3.1 方法对比
- 基于激光雷达的SLAM方法:用激光雷达匹配局部点簇的集合结构,生成局部精确地图
- 激光雷达里程测量方法:估算车辆的里程运动,并生成3D地图
以上两种方法在结构特征较少的时候,很难准确映射和定位
- 直接使用独立的位置估计传感器(如GPS/INS)提供里程计
上述方法成本太高
故引入视觉SLAM,利用ORB SLAM 的直接方法
3.2 语义分割
有很多方法可以使用:
– 利用多尺度卷积网络,从图像金字塔中提取多尺度特征
– 利用图像深度采取多尺度特征
– 生成用于对象的解析的多尺度 patch
随着基于特征增强的多尺度提取特征方法的发展,利用 PSPNet 方法,允许多尺度特征集成
3.3 语义映射
- 利用SVM分离可遍历与不可遍历场景
- 利用CRF-CNN进行语义分割
- 将现实世界的地标与语义3D地图相关联的研究还很少
4. Approach
- 以单目摄像头为传感器,聚焦于大城市区域

-
首先,将图像经过CNN进行图像分割
- 将像素级的映射结果和当前帧传给SLAM进行重建
- 利用ORB生成点云
- 利用贝叶斯关联,并更新概率分布
- 与GPS地图进行关联
- 由地标地图生成拓扑地图
B. Sematic Mapping
- 语义分割的目的是对于每个像素进行语义标签分类
- 利用ORB SLAM 进行三维重建和轨迹估计,具有良好的实时性
- 将语义与地图点进行关联,利用贝叶斯更新便签的概率分布
- 将特征点保存到点云中进行转换

其中:
(x_m,y_m,z_m) 是地图点在3D地图中坐标位置;
T_{pointcloud2camera} 是将点云位置转移到相机坐标中的参数矩阵;
(u_c,v_c) 是对应地图中点的摄像机像素。
每个特征点的标签的概率分布为:

其中:
F_s 是每一个标签经过语义分割部分后在当前帧中的概率分布;
L_m 是映射点中的标签。
由于每个特征点可以在不同的帧中被观测到,因此在不同的观测中应用了数据融合方法。采用贝叶斯更新进行多观测数据融合:

其中:
l^m_l 是坐标 k 处映射点 m 的标号;
\Zeta 是归一化常数;
p(l^m_l | F_{1:k},P_{1:k}) 是坐标 1 \sim k 的累积概率分布。
随着新的帧和点云的到来而更新结果,通过最大概率搜索每个地图点的最终标签

其中:
m 是单个地图点;
l^m 是 m 的地图标签。
C. GPS Fusion
- 将建筑地标与点云进行像素级的关联,生成语义点云
首先将坐标转换为笛卡尔坐标;再每个30帧,将当前帧作为采样点;再将姿态与经纬度添加到两个全局采样器中,利用奇异值分解求出两个矩阵的最佳旋转;如果比例不同,需要进行比例的变换

其中 \lambda 是比例乘法器;R 和 T 是两个所需要求出的最佳旋转

P_A 为笛卡尔坐标中的点集, centroid_A 为 P_A 的质心;
P_B 为姿态坐标中的点集, centroid_B 为 P_B 的质心。
当 R 和 T 被求出,建筑地标位置转换为点云坐标系的表示为

其中:
A 为笛卡尔点,为地标的位置;
B 为点云坐标中的点
D. Post Process
- 利用一个后期的处理来优化结果
- 地标级数据的融合
利用GPS信息与语义标签来将地标级数据与三维重建结果融合
在此时不会关注地标定位的准确性,而是关注地标位置的隶属度分布,用高斯概率分布评估位置隶属度
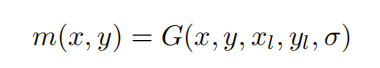
其中:
m(x,y) 为坐标 (x,y) 处的隶属度,
G(x,y,x_l,x_l,\sigma) 为二维高斯概率密度函数
(x_l,y_l) 为地标的位置。
以此实现基于路标的实时定位。
- 拓扑语义地图
该地图只包含地标及其几何关系之间的可达关系。语义映射中只有边和节点,更适合全局路径规划。
首先利用SLAM进行处理,保存摄像机的轨迹,再将地标与最近的关键帧相关联,保存与地标相关的关键帧和转向的关键帧,节点若被访问超过一次则地图被优化。(如果多个节点代表相同的地标或位置,将其与新节点融合)。

5. 实验





0 条评论