0. 论文链接
1. Abstract
现有的主流结构为 support-query, 该模型结构在小样本的情况之下受对于类内的变化的有限覆盖影响很大。
针对这种关键矛盾,本文提出了利用查询原型来匹配特征,其中查询原型从高置信度的查询预测之中收集。同时提出了自支持原型结构和自支持损失进行简化与优化。取得了目前最好,最先进的模型结果(SOTA)
2. Introduction
有限的小样本分割容易无法覆盖查询图像中目标类的底层外观变化,其根源在于:数据的稀缺性与多样性。现有的方法不能从根本上解决外观差异问题,局限于稀少的少样本支持度。
本文利用查询特征来自我支持。
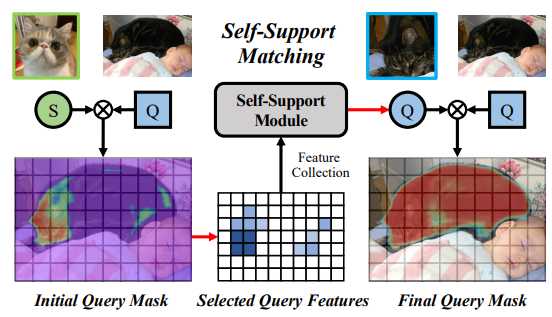
如上图所示,利用支持集和查询集来生成查询掩码,再利用查询掩码预测查询特征,利用查询特征生成查询原型以实现自匹配。
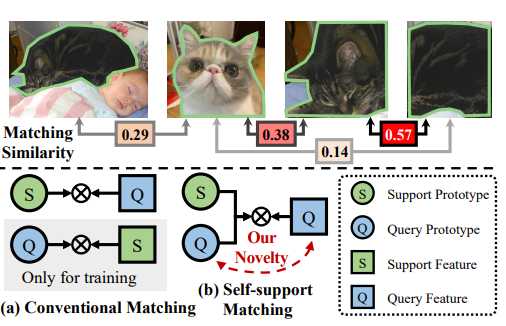
自支持匹配机制如图所示:相同物体的像素/区域比不同物体像素/区域更相似
本文的方法不是通过聚合所有背景像素来生成全局背景模型,而是动态聚合查询图像中的图像中的相似背景像素。同时使用灵活的自支持原型来匹配特征:通过有效捕获查询对象一致的底层特征,从而拟合匹配查询特征。
其他的方法可分为三种:
– 从额外的未标记图像中学习更好的支持原型用于匹配查询 (PPNet & MLC)
– 基于支持图像构建各种支持原型生成模块或特征先验 (PFENet)
– 使用查询原型来匹配支持特征,作为查询-支持匹配,仅用于辅助训练,不能解决外观差异(PANet & CRNet)
自支持方法通过缓解类内外观差异问题显著提高了原型质量
2.1 贡献
- 提出了新型的自主匹配方法,并构建了一种新型的自主网络来解决FSS中外观差异问题
- 提出了自支持原型,自适应自支持背景原型和自支持损失来促进自支持方法
- 自支持方法得益于更强的主干和更多的支持
3. Related Works
3.1 语义分割
语义分割是产生像素级密集语义预测的计算机视觉任务,近期的端到端的全卷积网络 FCN 提高了其效率,随后的工作也贡献了一系列的模型:如编-解码结构,图像和特征金字塔模块,上下文聚合模块和高级卷积层等。然而,上述分割方法在很大程度上依赖于丰富的像素级注释,本文要解决的是小样本情况下的语义分割
3.2 小样本学习
小样本学习的目的是在极少的样本中识别新概念。目前小样本学习的方法主要有以下三种:
– 迁移学习方法:通过两阶段的微调过程将从基类中学习到的先验知识适应到新类中
– 基于优化的方法:通过元学习从少数样本中建模优化过程
– 基于度量的方法:该方法在支持-查询对上应用暹罗网络来学习用于评估相关性的一般度量
本文的工作受到基于度量方法的启发
3.3 小样本语义分割
小样本语义分割结合了语义分割和小样本学习。主要采用了基于度量的主流范式+各种改进方式,如使用各种注意机制,更好的优化,内存模块的优化,图神经网络,基于学习的分类器和渐进匹配等。
现有的所有方法在支持匹配中存在严重的类内差异问题,故本文的矛盾重点在于消除类内的差异问题。
4.自支持小样本语义分割
目前的FSS很大程度上依赖于支持原型来分割查询对象,通过将每一个查询像素与支持原型密集匹配,此方法严重受到类内外观差异的影响。
故本文建议使用查询特征生成查询特征本身匹配的自支持原型,这种原型使查询沿着同源的查询特征对齐,从而可以显著缩小支持和查询之间的特征差距,而该方法更优的原因在于对于给定的可视对象类,对象内部的相似性远远高于跨对象的相似性
其主流方案的流程如下:
4.1 自支持原型
其核心思想是聚合查询功能以生成查询原型,并用它来自我支持查询功能本身
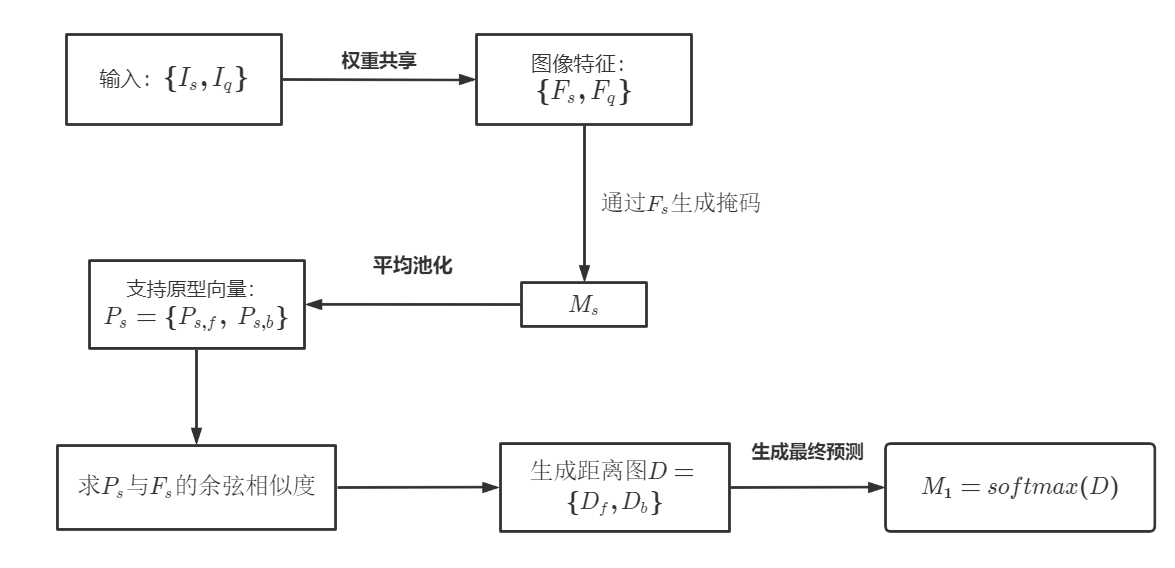
常规生成支持原型的过程如下:
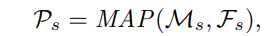
其中 MAP 为掩码平均池化操作,用于生成带有查询特征 F_q 的匹配预测.同样的,用相同的方法生成查询原型 P_q,其过程可写成公式:
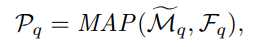
利用查询原型 P_q 来匹配查询特征
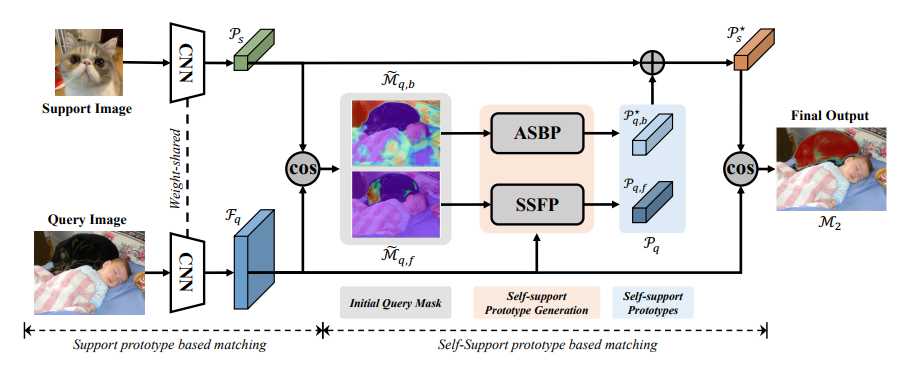
如上图所示,首先使用传统的基于支持原型的匹配网络生成初始掩码预测,再利用初始掩码聚合查询特征,生成自支持原型。
为了验证部分对象或对象片段是否能够支持整个对象,使用部分原型训练的评估模型,这些模型是根据掩码标签随机选择特征聚合而成。进一步在部分原型中加入噪声特征(20%),发现工作性能仍然很好。
4.2 自适应自支持背景原型
前景像素往往具有语义共性,可以利用掩码平均池化操作生成自支持前台原型,而背景往往是混乱的,导致背景像素之间没有共享的全局语义共性。
传统的利用聚类算法直接对多个背景进行分组,然后对每个像素找最相似的原型进行匹配的方法不稳定且耗时。故采用动态聚合相似的像素背景,生成自适应自支持背景原型的方法。
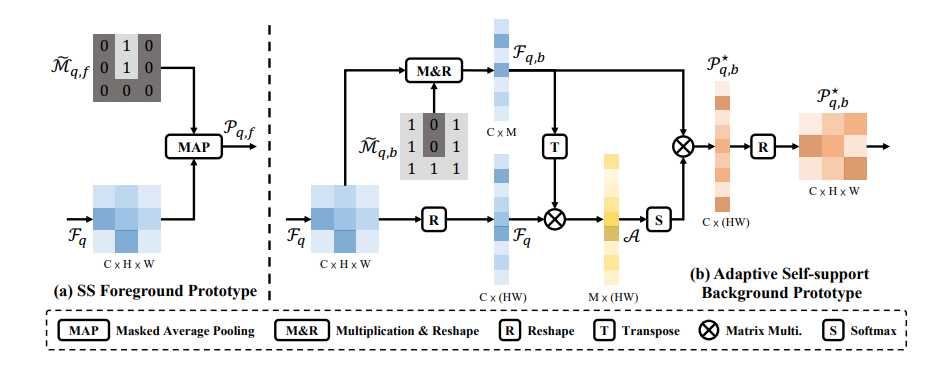
上图是自适应自支持前景原型和自适应自支持背景原型的生成过程。
具体流程如下:
对于自适应自支持前景原型而言,利用估计查询掩码 \widetilde{M}_ {q,f} 和 F_q 通过 MAP 操作生成前景查询原型 P_{q,f}。
对于自适应自支持背景原型而言,要将 \widetilde{M}_ {q,b} 与 F_q 相乘并转换为向量,生成 F_{q,b},其次将 F_q 转换为向量,将 F_{q,b} 转置并与 F_q 矩阵相乘,生成亲和矩阵 A,将亲和矩阵 A 进行 softmax 操作后与原 F_{q,b} 矩阵相乘,再转换成 C\times H \times W 的矩阵 P^{*}_ {q,b}。
通过以上操作,自支持原型就被更新为自适应自支持背景原型 P_q=\{P_{q,f},\ P^{*}_ {q,b}\}
4.3 自支持匹配
将支持原型 P_s 与自支持原型 P_q 加权组合:P^{*}_ {s}=\alpha_1 P_{s}+\alpha_2 P_q,在实验中 \alpha_1=\alpha_2=0.5。
计算增强支持原型 P^{*}_ {s} 与 F_q 之间的余弦距离以生成最终的预测:
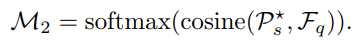
再生成距离图:
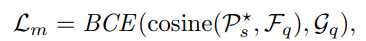
其中 BCE 为二进制交叉熵损失, G_q 为查询图的真实掩码。
为简化自支持匹配过程,提出一个新的查询自支持损失的方法:
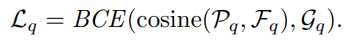
利用相同的步骤到支持特征上引入自支持匹配损失 L_s,最终以端到端的训练模型联合优化上述损失:
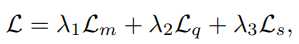
其中 \lambda_1=1.0,\lambda_2=1.0,\lambda_3=0.2
5. 相关实验
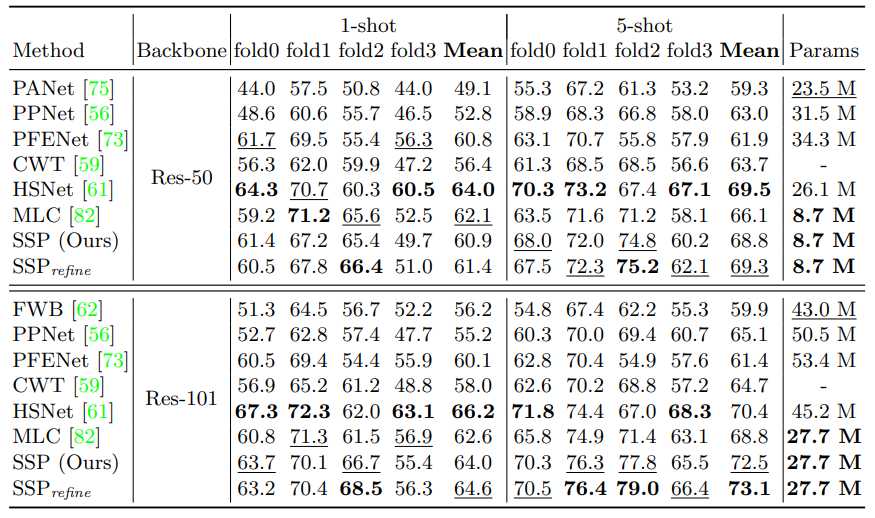
上图为 PASCAL-5^i 数据集的定量比较结果,最佳和次优结果分别用粗体和下划线突出显示。
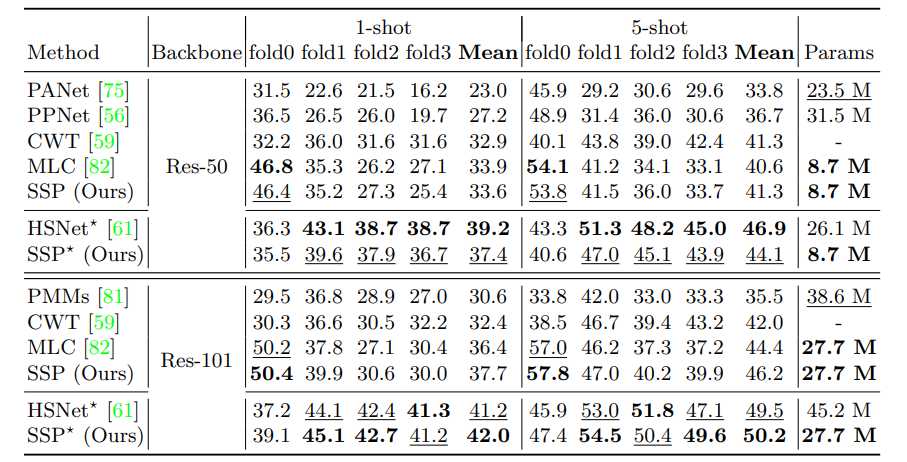
上图为 COCO-20^i 数据集的定量比较结果,* 表示根据 HSNet 的评估协议评估结果。
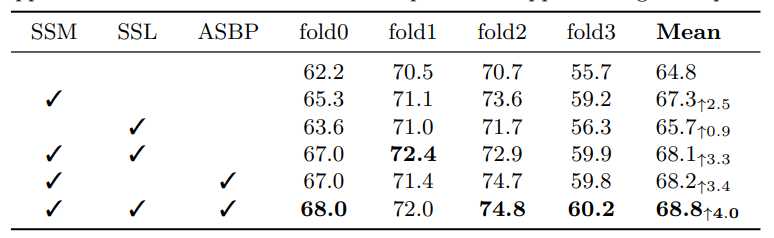
自持模型消融结果。“SSM”表示自助模块(包含自助前台/后台原型),“SSL”表示自助损失,“ASBP”表示自适应自助后台原型
自支持模块显著提高了2.5%的性能。自支持损失进一步简化了自立过程,将绩效提升到68.1%。基线模型受益于额外监督的自支持损失。在配备自适应自支持背景原型后,自支持模块可额外获得0.9%的增益。整合所有模块,我们的自支持方法意义重大,基于强基线将性能从64.8%提高到68.8%。
5.1 自支持分析
由于对象之间/背景之间的变化很大,预测通常只捕获一些小的代表区域,而自支持的方法可以弥合查询和支持原型之间的差距来处理。
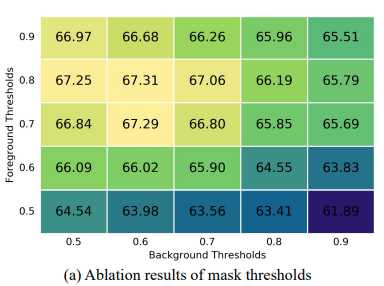
上图是自支持原型的掩码阈值变化结果

上表是分别去处 FP,BP,SFP,SBP 对于 SSM 的消融结果
本文的方案不同于自注意机制,自注意增强机制会破坏查询与支持项之间的特征相似性,同时自适应自支持原型生成是专门为自支持原型设计,不能直接应用于支持原型的生成。
5.2 自支持优点
- 受益于骨干和支持
- 高置信度的预测
- 强支持标签的鲁棒性
- 可推广的其他方法
- 效率高
6. 总结
通过 F_q 和 SSP,并与 F_q 进行自支持匹配解决了小样本分割中固有的关键类内外观差异问题。有效缩短了 SP 和 F_q 之间的差距提出 SBP 和 SSL 简化 S-S 过程


0 条评论