0. 论文
1. Abstract
对于原型学习来说,通常通过平均全局对象的信息,从支持特征中获取单个原型,但是单个原型来表示所有信息可能导致歧义。
在本文中,提出了超像素引导聚类 SGC 以及 引导原型分配 GPA 两个模块,用于多原型的抽取与匹配。SGC 是一种无参数,无训练的聚类方法,GPA 是为选择匹配的原型提供更准确的指导。利用 SGC 和 GPA 两个模块构成自适应超像素引导网络 ASGNet
2. Introduction
目标是学习在给定的查询图像中分割对象,其中只有少数具有真实分割掩码的支持图像可用。
目前小样本分割通常从查询图像和支持图像中提取特征,提出不同的特征匹配和对象掩码从支持图像到查询图像的转换方法。这种特征匹配和掩码迁移通常以两种方式:原型特征学习/亲和学习,其中原型特征学习比像素特征对于噪声的鲁棒性更好。对于亲和学习而言,在尝试用密集亲和矩阵解决约束不足的像素匹配问题时,容易对训练数据进行过拟合。
在本文的工作中,希望根据图像的内容自适应地改变原型的数量及其空间范围,使原型具有内容自适应能力和空间感知能力。这种自适应能力对于处理物体的大小和形状非常重要。目标是根据特征相似度将支持特征划分为几个有代表性的区域。
在本文提出的两个模块中, SGC 模块对支持图像进行基于特征的快速超像素的提取,所得到的超像素的质心被视为原型特征。由于超像素的心中和数字对图像的内容是自适应的,故产生的原型也是自适应的。 GPA模块则使用一种类似注意力的机制,将最相关的特征原型分配给查询图像中的每一个像素。
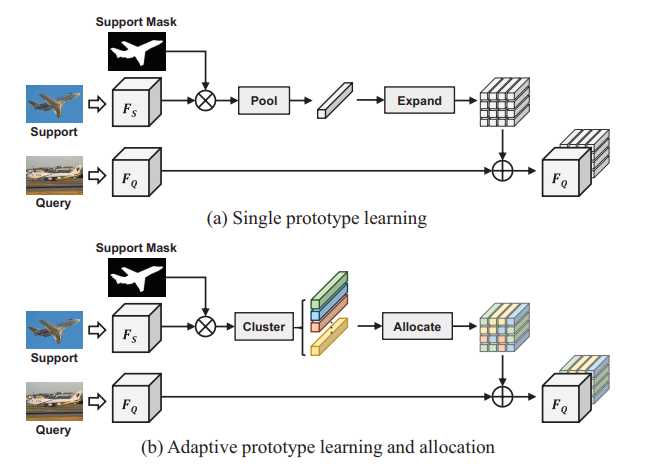
上图为单一原型学习与提出的自适应原型学习与分配的比对。利用超像素引导聚类来生成多个原型,然后按像素分配它们来查询特征
本文的贡献在于以下几点:
- 提出了自适应超像素引导网络(ASGNet)。这是一种灵活的小样本分割的原型学习方法,适用于不同的物体尺度,形状和遮挡
- 引入两个新模块 —— SGC 和 GPA,分别用于原型的提取以及分配
- 提出的 ASGNet 能以更少的参数和更少的计算实现最佳性能的结果
3. 相关工作
3.1 语义分割
现有的大多数语义分割都是基于 FCN,主要来自多尺度特征聚合或注意力机制。这些方法的缺点在于:需要很长的训练时间和大量像素级编辑的真实情况来全面监督网络,此外,在推断阶段,训练过的模型无法识别训练集中不存在的新类
3.2 小样本学习
现有的小样本学习主要基于度量学习和元学习。而本文的方法基于度量学习的启发
3.3 小样本分割
小样本分割是小样本分类的一个扩展。发展至今已经提出了很多方法,如基于原型思想的 PL,基于掩码平均池化操作的 SGOne,利用原型对齐正则化的 PANet,将原型扩展到与查询特征相同大小的 CANet,在支持特征和查询特征之间引入密集的像素-像素连接的 PGNet,BriNet,DAN,利用期望最大化算法生成多个原型的 PMMs 等。
在本文的工作中,利用每一个原型和查询特征之间的相似性选择每个像素位置上最相关原型。
3.4 超像素
超像素被定义为一组具有相似特征(颜色、纹理、类别)的像素。超像素已经在许多计算机视觉任务中发挥了重要作用,并被用作图像分割任务的基本单元。超像素比像素携带更多的信息,可以为下游视觉任务提供更紧凑和方便的图像表示。
3.5 问题分析
小样本分割与一般的语义分割的关键区别在于训练集中和测试集中的类别不相关。这就意味着,在推断阶段,测试集具有训练中完全未学习的类。
4. 本文解决方案
提出了两个模块 SGC 和 GPA,将两个模块结合,生成 ASGNet。
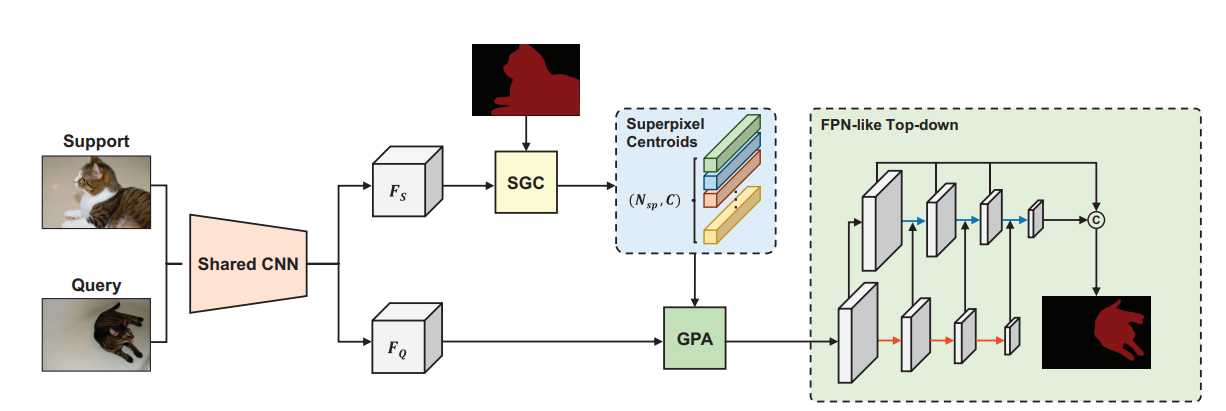
4.1 超像素引导聚类 SGC
SGC 收到 SSN 的启发。SSN 将 SLIC 中的最近邻操作转换为可微操作,传统的 SLIC 超像素算法采用 k-均值迭代聚类,分类像素-超像素关联和超像素质心更新两步
将特征图以聚类的方式聚合成多个超像素质心。超像素质心可以作为原型,不在图像空间中计算超像素质心,而是通过聚类相似特征向量在特征空间中估计它们。具体的算法如下:

给定支持特征 F_s \in R^{c\times h \times w},支持掩码 M_s\in R^{h\times w} 和初始化超像素种子 S_0\in R^{c\times N_{sp}},其中 N_{sp} 为超像素的个数。
先将绝对坐标连接到 F_s,通过支持掩码 M_s 提取掩码特征 F\’_ s ,定义距离函数为:
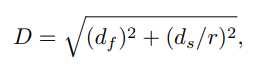
其中 d_f 为特征的欧氏距离,d_s 为坐标值的欧式距离,r 为权重因子。
利用支持掩码过滤掉背景信息,只保留被掩码的特征。将 F_s\in R^{c\times w \times h} 压缩到 F’_ s\in R^{c\times N_m},其中 N_m 为支持掩码内的像素数量。
根据距离函数 D 计算每个像素 p 和所有超像素之间关联映射 Q^t
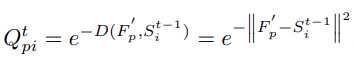
将新的超像素质心更新为掩码特征的加权和
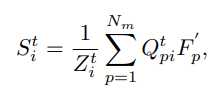
其中 Z^t_i=\sum_pQ^t_{pi} 为归一化的常数。
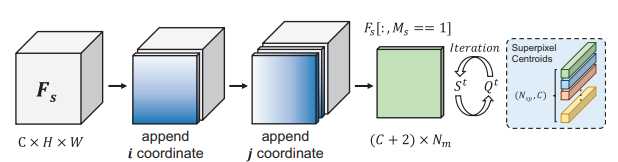
在本文的工作中,已经为支持图像提供了前景蒙版,只需要初始化前景区域内的种子,为了在掩码区域中统一初始化种子,引用 MaskSLIC 来迭代放置每个初始种子。这种种子初始化使得超像素引导聚类的收敛速度更快,只需要几次迭代。
4.2 引导原型分配 GPA
为了使原型匹配更适应查询图像的内容,提出了引导原型分配 GPA。
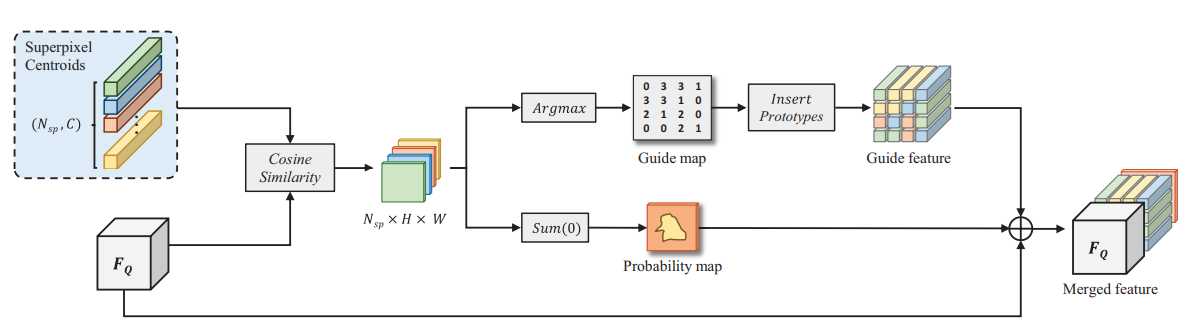
首先计算出余弦距离来衡量每个原型和每个查询特征元素之间的相似性
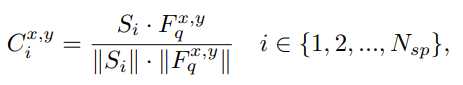
其中 S_i 为第 i 个超像素质心,F_q^{x,y} 是查询特征在 (x,y) 处位置的特征向量。利用相似度信息计算每个像素位置上哪个原型最相似。
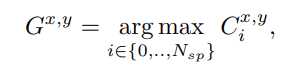
G^{x,y} 表示特定原型的单个索引值。将所有指标放在一起得到导图 G,在 G 内每个位置放置相应的原型,得到导图的特征 F_G,实现逐像素引导,而在另一分支中将所有超像素的相似度信息 C 相加,得到概率图 P。
最后,将概率图和引导特征与原始查询特征 F_Q 进行拼接,提供引导信息,从而得到精细化的查询特征 F’_ Q。
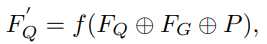
其中 \oplus 表示沿信道维度的级联运算,f(\cdot) 表示 1\times 1 的卷积。
4.3 适应性
本文提出的网络的一个关键属性之一就是其对于小样本语义分割的自适应能力。

在 SGC 中,为使其适应对象尺度,定义了一个标准来调节超像素质心的数量为
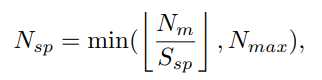
其中 N_m 为支持掩码的像素数量, S_{sp} 是分配给每个初始超像素种子的平均面积, N_{sp}=0/1 时,该操作退化为一般的平均化操作,同时设置超参数 N_{max} 来限制原型的最大数量。
在 GPA 中,当查询图像有严重遮挡时, GPA 可以为每一个查询特征位置选择最匹配原型。
4.4 自适应超像素引导网络 ASGNet
首先,将支持和查询图像输入共享 CNN 上以提取特征,再将支持特征通过带有支持掩码的 SGC 传递得到超像素质心,并将其视为原型,在此基础上,采用 GPA 模块来匹配原型和查询功能,最后使用特征丰富模块,建立一个自顶向下的结构来引入多尺度信息。将所有不同的标度进行拼接,每个尺度将得到一个分割结果,用于计算损失。
4.5 K-shot 设置
在以往的工作中,通常通过特征平均和基于注意力机制融合解决,改进效果较小且计算量较大。本文的工作中,对每个支持图像和掩码对中,用 SGC 获取超像素质心,通过收集这些质心,从 k-shot 中获取了整体的超像素质心 S
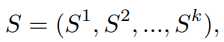
这样一来,GPA 可以接收更大范围的选择,产生更准确的指导。
5. 实验
本文工作使用 Pascal-5^i 和 COCO-20^i 数据集,使用平均交叉联合作为消融研究的主要评估指标。采用 ResNet 作为骨干网络。
5.1 消融研究
超像素质心数量
在实验中发现,与使用固定的超像素相比,自适应设置可以减少冗余计算,同时可以获得更好的性能。
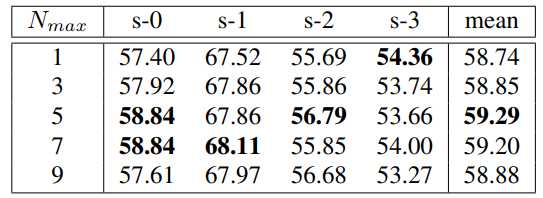
超像素质心最大数目Nmax的烧蚀研究。S-x表示不同的交叉验证分割。
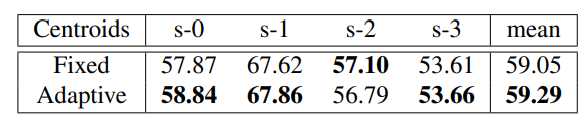
固定和自适应超像素质心的性能比较。
SGC 和 GPA
首先实现一个基线模型,使用单原型学习,然后引入 SGC 生成多个原型再进行密集融合,最后将原型扩展替换为分配方案。
在 1-shot 情况下性能下降,但在 5-shot 情况下性能得到一定提升。得到该结果的主要原因是过多原型再单个支持样本上变得高度相似,余弦距离无法将它们区别开。
最后,采用GPA模块进行原型匹配时,与原型扩展相比,性能提高了2.70%,计算开销也大大降低。
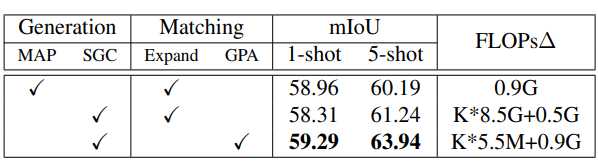
上表为原型生成(MAP vs SGC)和匹配(Expand vs GPA)的消融研究。FLOPs∆为原型匹配过程的计算代价,K为原型自适应数(K≤5)。
K-shot 融合设置
对于特征平均融合和注意力加权求和两种方法进行比较。结果 1-shot 得到最佳提升。而相反,基于注意力机制的融合需要大量的计算,并且性能提升有限。在给出大量选择时,GPA模块非常有效。
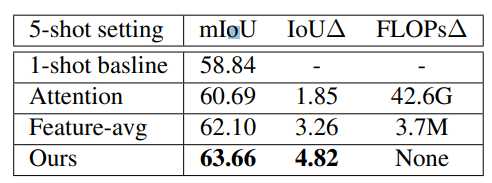
不同 k-shot 融合策略的消融研究
5.2 与最先进技术对比
本文提出的 ASGNet 在 5-shot 下取得了较先进水平的显著改进,在 1-shot 下也有 5.0% 的最大性能提升
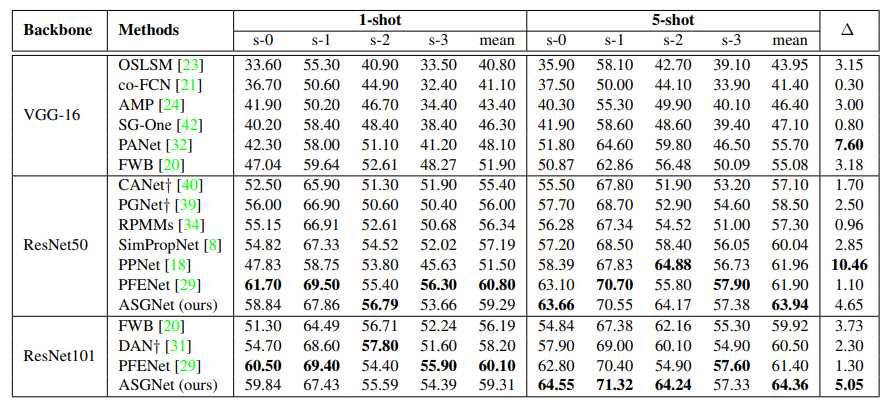
与 Pascal-5i 最先进技术的比较。†表示采用多尺度推理。∆ 为 1-shot 分割结果的增量。
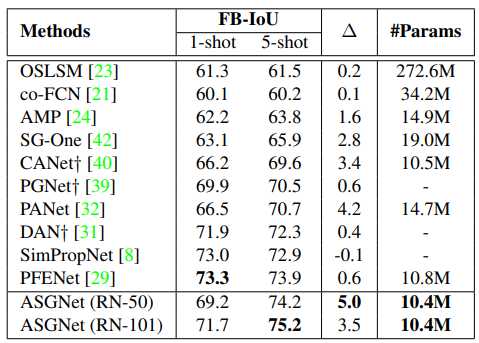
Pascal-5i 上 FB-IoU 与可训练参数数量的比较。† 表示采用多尺度推理。∆ 为 1-shot 分割结果的增量
ASGNet 在平均 IoU 的 1-shot 和 5-shot 都达到了最先进结果。
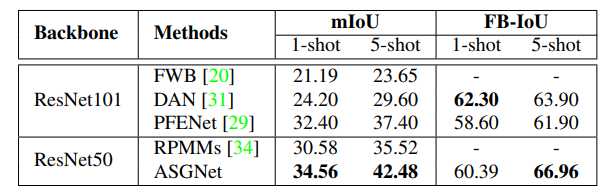
在 COCO-20i 数据集上与世界先进水平的比较
6. 总结
本文提出了一种用于少镜头图像分割的 ASGNet 算法。针对现有基于单个原型的模型的局限性,我们引入了两个新的模块,称为超像素引导聚类(SGC)和引导原型分配(GPA),用于自适应原型学习和分配。具体而言,SGC 通过基于特征的超像素聚类聚合相似特征向量,GPA 通过余弦距离测量相似度,为每个查询特征元素分配最相关的原型。大量的实验和消融研究已经证明了 ASGNet 的优越性,我们在 Pascal-5i 和 COCO-20i 上都实现了最先进的性能,而无需任何额外的后处理步骤。


0 条评论